Quick Start¶
This sections gives simple boilerplate code using gym-os2r to perform a simulation of the physical monopod. This simulation provides an environment that parallels the physical properties of the real monopod for reinforcement learning research compatible with OpenAI Gym.
Following the structure of gym-ignition we provide the following classes to train a model for the monopod:
runtime: Provides the code that deals with real-time execution for environments running on the real robot. The implementation for the physical platform isRealtimeRuntime.monopod: Provides the structure of the decision-making logic for the monopod. The code of the task is independent from the runtime, and only the core ScenarIO APIs should be used. The active runtime will then execute the task on either simulated or real worlds by selecting the scenario implementation.gym_os2r.randomizers: Randomizer acts as agym.Wrapperclass that randomizes the domain of the simulated environment every rollout. The two randomizes provided aregym_os2r.randomizers.monopodandgym_os2r.randomizers.monopod_no_rand.gym_os2r.rewards.RewardBase: Abstract base class that provides a simple interface to implement new rewards functions. This class can be passed into themonopod*kwargs.
A minimal example for gym-os2r. This example creates a monopod environment then
performs random actions.
Minimal Example¶
import gym
import time
import functools
from gym_ignition.utils import logger
from gym_os2r import randomizers
from gym_os2r.common import make_env_from_id
# Set verbosity
# logger.set_level(gym.logger.ERROR)
logger.set_level(gym.logger.DEBUG)
env_id = "Monopod-stand-v1"
kwargs = {}
make_env = functools.partial(make_env_from_id, env_id=env_id, **kwargs)
# env = randomizers.monopod.MonopodEnvRandomizer(env=make_env)
env = randomizers.monopod_no_rand.MonopodEnvNoRandomizer(env=make_env)
# Enable the rendering
env.render('human')
# Initialize the seed
env.seed(42)
for epoch in range(1000):
# Reset the environment
observation = env.reset()
# Initialize returned values
done = False
while not done:
# Execute a random action
action = env.action_space.sample()
observation, reward, done, _ = env.step(action)
env.close()
time.sleep(5)
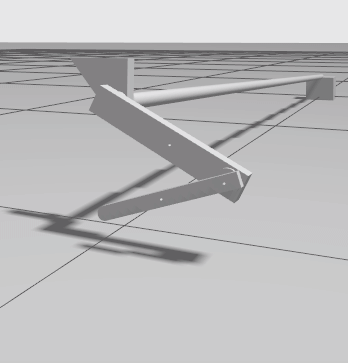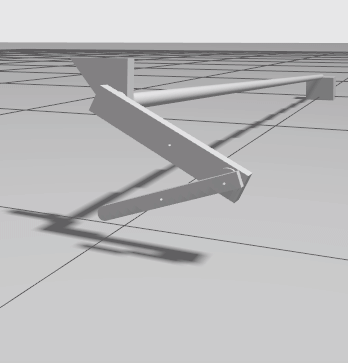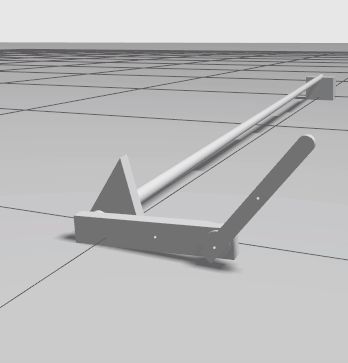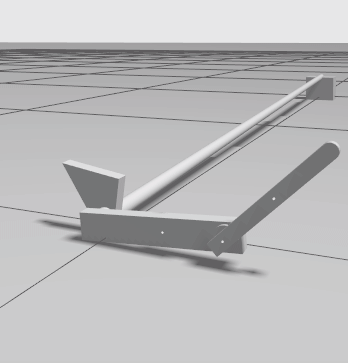
Example of the simulation. The minimal example performs random actions until it reaches the maximum time steps.¶
Environment Ids¶
The provided environment ids with their corresponding kwargs are listed in the table below.
Environment Id |
task_mode |
reward_class |
reset_positions |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Kwarg Options¶
The gym-os2r package provides multiple kwargs for ease of customizing the
environment. The available kwargs are listed in the attributes of the
monopod class. The following table concisely lists all the
different options:
Required |
Type |
Description |
Available Options |
|---|---|---|---|
|
str |
Defines the configured mode of the monopod i.e. how many actuated joints and how many observed joints. |
|
|
Defines the reward function for the task. The reward class has access to the previous action and the current observation. |
Provided reward functions: |
|
|
[str] |
Array of allowed positions for the monopod to be reset into. This will be randomly chosen during each reset. |
|
Example of how to specify the kwargs in the env. Replace the kwargs with the
ones that are desired.
from gym_os2r import randomizers
from gym_os2r.common import make_env_from_id
from gym_os2r.rewards import BalancingV1
env_id = "Monopod-stand-v1"
kwargs = {
'task_mode': 'free_hip',
'reward_class': BalancingV1,
'reset_positions': ['float', 'lay', 'stand']
}
make_env = functools.partial(make_env_from_id, env_id=env_id, **kwargs)
env = randomizers.monopod_no_rand.MonopodEnvNoRandomizer(env=make_env)
Default Reset Positions¶
The reset positions shipped with the environment are all shown below. You can choose any number of these positions to train with.
|
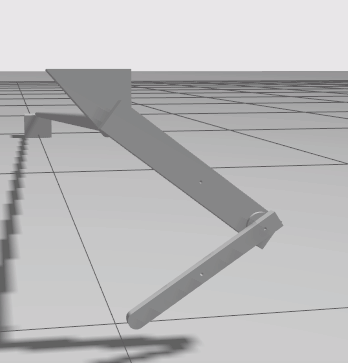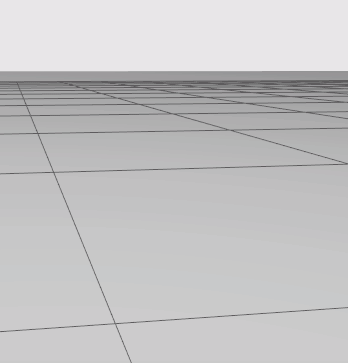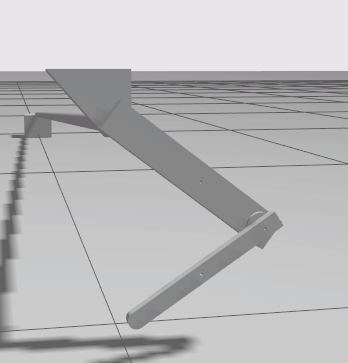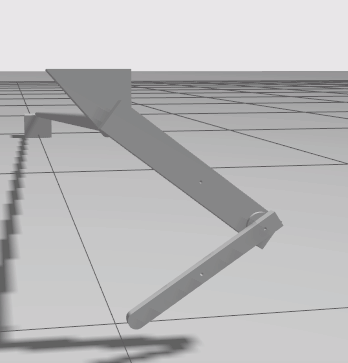
|
|

|
|
Default Randomizer Features¶
Randomized Property |
Method |
Distribution |
Note |
|---|---|---|---|
|
Scale |
|
Mass of each link in the robot is scaled between 80% and 120% of the default value. The scaling is sampled from a uniform distribution. |
|
Absolute |
|
Joint frictions are sampled from a uniform distribution between 0.01 and 0.1. |
|
Scale |
|
Dampening of each link in the robot is scaled between 80% and 120% of the default value. The scaling is sampled from a uniform distribution. |
|
Absolute |
|
Ground planes surface frictions is sampled from a uniform distribution between 0.8 and 1.2. |
|
– |
– |
Link inertia needs to satisfy the triangle inequality. This means the the link inertia can only have scaling trivially. Will add better randomization in future. Track feature here. |
To use domain randomization while training only one line of code is required to change. The following code block illustrate this.
from gym_os2r import randomizers
from gym_os2r.common import make_env_from_id
from gym_os2r.rewards import BalancingV1
env_id = "Monopod-stand-v1"
make_env = functools.partial(make_env_from_id, env_id=env_id, **kwargs)
env = randomizers.monopod.MonopodEnvRandomizer(env=make_env)